

Consider what happens to cache memory when a thread has been running on a specific processor. The data most recently accessed by the thread populate the cache for the processor. As a result, successive memory accesses by the thread are often satisfied in cache memory (known as a "warm cache"). Now consider what happens if the thread migrates to another processor - say, due to load balancing. The contents of cache memory must be invalidated for the first processor, and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most operating systems with SMP support try to avoid migrating a thread from one processor to another and instead attempt to keep a thread running on the same processor and take advantage of a warm cache. This is known as processor affinit - that is, a process has an affinity for the processor on which it is currently running.
The two strategies, common ready queue and per-core queues, for organizing the queue of threads available for scheduling have implications for processor affinity. If we adopt the approach of a common ready queue, a thread may be selected for execution by any processor. Thus, if a thread is scheduled on a new processor, that processor's cache must be repopulated. With private, per-processor ready queues, a thread is always scheduled on the same processor and can therefore benefit from the contents of a warm cache. Essentially, per-processor ready queues provide processor affinity for free!
Processor affinity takes several forms. When an operating system has a policy of attempting to keep a process running on the same processor - but not guaranteeing that it will do so - we have a situation known as soft affinit. Here, the operating system will attempt to keep a process on a single processor, but it is possible for a process to migrate between processors during load balancing. In contrast, some systems provide system calls that support hard affinit, thereby allowing a process to specify a subset of processors on which it can run. Many systems provide both soft and hard affinity. For example, Linux implements soft affinity, but it also provides the sched_setaffinity() system call, which supports hard affinity by allowing a thread to specify the set of CPUs on which it is eligible to run.
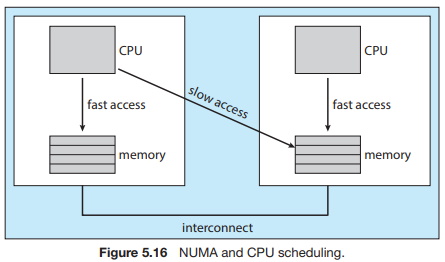
The main-memory architecture of a system can affect processor affinity issues as well. Figure 5.16 illustrates an architecture featuring non-uniform memory access (NUMA) where there are two physical processor chips each with their own CPU and local memory. Although a system interconnect allows all CPUs in a NUMA system to share one physical address space, a CPU has faster access to its local memory than to memory local to another CPU. If the operating system's CPU scheduler and memory-placement algorithms are NUMA-aware and work together, then a thread that has been scheduled onto a particular CPU can be allocated memory closest to where the CPU resides, thus providing the thread the fastest possible memory access.
Interestingly, load balancing often counteracts the benefits of processor affinity. That is, the benefit of keeping a thread running on the same processor is that the thread can take advantage of its data being in that processor's cache memory. Balancing loads by moving a thread from one processor to another removes this benefit. Similarly, migrating a thread between processors may incur a penalty on NUMA systems, where a thread may be moved to a processor that requires longer memory access times. In other words, there is a natural tension between load balancing and minimizing memory access times. Thus, scheduling algorithms for modern multicore NUMAsystems have become quite complex.
To learn more about Processor Affinity, Heterogeneous Multiprocessing, and Real-Time CPU Scheduling, see The tenth edition of Operating System Concepts page 224.
About the Authors
Abraham Silberschatz is the Sidney J. Weinberg Professor of Computer Science at Yale University. Prior to joining Yale, he was the Vice President of the Information Sciences Research Center at Bell Laboratories. Prior to that, he held a chaired professorship in the Department of Computer Sciences at the University of Texas at Austin.
Professor Silberschatz is a Fellow of the Association of Computing Machinery (ACM), a Fellow of Institute of Electrical and Electronic Engineers (IEEE), a Fellow of the American Association for the Advancement of Science (AAAS), and a member of the Connecticut Academy of Science and Engineering.
Greg Gagne is chair of the Computer Science department at Westminster College in Salt Lake City where he has been teaching since 1990. In addition to teaching operating systems, he also teaches computer networks, parallel programming, and software engineering.

The tenth edition of
Operating System Concepts
has been revised to keep it fresh and up-to-date with contemporary examples of how operating
systems function, as well as enhanced interactive elements to improve learning and the student's
experience with the material. It combines instruction on concepts with real-world applications
so that students can understand the practical usage of the content. End-of-chapter problems,
exercises, review questions, and programming exercises help to further reinforce important
concepts. New interactive self-assessment problems are provided throughout the text to help
students monitor their level of understanding and progress. A Linux virtual machine (including
C and Java source code and development tools) allows students to complete programming exercises
that help them engage further with the material.
A reader in the U.S. says, "This is what computer-related books should be like. It is thorough, in depth, information packed, authoritative, and exhaustive. You cannot get this kind of excellent information from the Internet - or many other computer books these days. It's a shame that quality computer books are declining so rapidly in number. I hope they continue to update and publish this book for many years to come.

More Computer Architecture Articles:
• Operating System Memory Paging Hardware Support
• Program Flow Charting
• CPU Chip Packaging
• Operating System Memory Page Sharing
• The Android Operating System
• Intel's Core i7 Processors
• Operating System Memory Management
• The Fetch, Decode, Execute Cycle
• Stored Program Architecture
• Digital Logic Levels and Transfer Characteristics